

できるエンジニアになるためのちょい上DB術/第2章 概念設計
3.3 論理設計の手順(2/4)
3.3.3 最適化
収集された業務に関するデータと、アプリケーション開発側で定義された処理要件より、性能を発揮するための最適化処理を考えます。
最適化のポイントは、プロセス側で変更が起きた場合の影響を最小限にし、正規化をなるべく崩さないことです。
具体的な方法として、論理設計では索引と非正規化を考えます。
索引の検討
B*treeインデックスとは
B*treeインデックスは、RDBMSで使用されている最も標準的なインデックスです。
実際にはB-tree、B+tree、そしてB*treeという進化の過程がありますが、現在一般的に使われているB*treeを説明します。
下記に構造のイメージ図を示します。
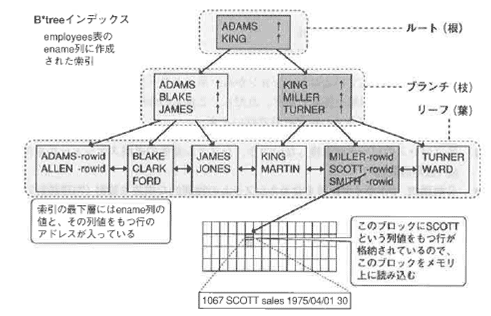
木をひっくり返した階層構造になっています。
一番上のレベルが根、真ん中が枝、一番下の階層を葉と呼びます。
B*treeインデックスは、RDBMSで使用されている最も標準的なインデックスです。
実際にはB-tree、B+tree、そしてB*treeという進化の過程がありますが、現在一般的に使われているB*treeを説明します。
下記に構造のイメージ図を示します。
インデックス作成時
まず、この構造がどうやって作成されるかを説明します。
図3-2は、employees表(従業員表)のename列に索引を作成した結果、作成されたものです。
1.すべてのename列の列値をソートして、列値とその列値をもつ行のアドレス=rowidを、ソート順にリーフノードに格納します。
列値とその列値をもつ行のアドレス=rowidを索引エントリと呼びます。 索引作成時の注意書項を示します。
- B*treeインデックスにはnull値は格納されません。
つまり、条件式にnull値を検索する場合、索引を使用することはできないことになります。 - ブロック内に新規索引エントリを挿入する際、新しい索引エントリのために、ブロック内に空き領域を確保しておきます。
これは、索引作成時のパラメータPCTFREEで設定することができます。 - リーフノードには双方向にお互いのブロックアドレスが格納されていて、範囲検索を行う場合でも、
上位のブロックに戻って検索しなくてもすむようになっています。
2.リーフノードが満たされると、リーフノードの先頭の列値と、リーフノードのブロックアドレスを順次ブランチノードの
エントリに格納していきます。
3.必要な数だけブランチブロックが作成されると、最後にブランチブロックを参照するルートノードのブロック内の
エントリを作成します。
検索時:インデックス使用時
1.検索条件に指定された値をルートノードから比較して探していき、最終的にリーフノードで該当の列値を
もつ行アドレス(rowid)を取得します。
行アドレス(rowid)からブロックアドレスを取得することができます。
ブロックアドレスから、まずメモリ上に該当行を含むブロックがあるかを探します。
次に、アクセスすべきブロックがメモリ上になければ、ブロックをディスクから読み込むことになります。
2.ブロックをメモリ上に読み込んだら、当該ブロックにアクセスして行データを取得します。
アクセスする対象となるブロック数が少なければ、索引によるアクセスの効果は高いということができますが、
逆に対象となる行数が多く、それに伴ってアクセスブロック数が多い場合には、1ブロックごとにアクセスする
必要があり、連続した複数ブロックの読み込みができる全表検索と比べて索引の効果があまり高くならない場合もあります。
インデックスを作成した表にDML文が発行されたとき
- Insert時:索引を作成した列傾が新規に入ってきたときは、ソートされた順に、該当するブロックに索引エントリが挿入される必要があります。
もしリーフブロックがいっぱいになっていた場合、新規に索引用のブロックをリーフノードに追加し、前後のブロックの空き領域の割合が同等になるように索引エントリの数が調整されます。
次に、ブランチブロックに新しいブロックの先頭エントリとブロックアドレスを追加します。 - Delete時:Oracleではエントリの物理削除は行わず、論理削除のみ行います。
論理削除では、削除されたエントリ領域の再使用はできません。
ブロック領域が再使用できるのは、すべてのエントリが論理削除されたときなので、論理削除が多くなると、領域の使用効率が悪くなります。 - Update時:索引のエントリはソートされているので、同じ索引エントリの列値だけ更新することはできません。
その索引エントリの論理削除と新規索引エントリのInsertを実行することになります。
仕組みがわかったところで、次に索引を使ったときとそうでないときの検索の仕組みの違いを説明します。
それが理解できると、どのような列に索引を作成すべきか、いつ索引を使用すると効果的なのかがわかります。
