

4.5 パフォーマンスアップ
4.5.2 統計情報の収集
統計情報を収集するための代表的な2つの方法を説明します。
ANALYZEコマンドとDBMS_STATSパッケージです。
2つともほぼ同じ機能をもっていますが、DBMS_STATSパッケージを使用すると、統計情報を収集する単位を指定して、まとめて収集することができます。
収集する単位とは、表単位、ユーザ単位、データベース単位などを指し、どの単位でまとめて統計情報を収集するかによって、プロシージャを使い分けます。
- ANALYZEコマンド テーブルの全行情報を収集(小さい表の場合)
- ANALYZE TABLEスキーマ名.テーブル名[PARTIT10N(パーティション名)]
COMPUTE STATISTICS[for_clause];
テーブル内サンプリング情幸別文集(大規模な表の場合、サンプリングしないと、統計情報収集のみで数時間かかる可能性がある。サンプリング率は5%~10%) - ANALYZE TABLEスキーマ名.テーブル名[PARTITlON(パーティション名)]
ESTIMATE STATISTICS[(for_clause)SAMPLE integer{ROWS | PERCENT}];
【for_clause句構文】
FOR {TABLE | ALL INDEXED COLUMNS SIZE integer |
COLUMNS SIZE integer column SIZE integer * | ALL LOCAL INDEXES}
SIZE integerはヒストグラムのバケット数
ヒストグラムの統計情報は、値によって該当する行数が著しく異なるような列に対して作成すると効果的です。
たとえば、「性別」という列の値に「男性」と「女性」しかない場合でも、「女性」の行が全体の1%だった場合、WHERE条件式で「WHERE 性別='女性'」のような指定があった場合、「性別」列に索引を作成しておき、ヒストグラム統計をとることによって、値に「女性」と指定された場合のみ索引を使用するという選択ができます。
SIZE句で指定するintegerは、バケット数を指定します。
バケット数が多いほど正確な統計値を取得できますが、統計の取得に時間がかかります。
ヒストグラム統計はすべての列に取得する必要はなく、値によって索引の使用が効果的だと思われる列にだけ作成してください。
- DBMS_STATS.GATHER_TABLE_STATS
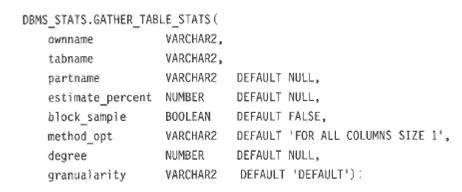
- partname: パーティション名
- estimate_percent:
サンプリングする行のパーセンテージ
適切な統計を行うための最適なサンプルサイズを0racleで決定するためには、定数DBMS_STATS.AUTO_SAMPLE_SIZEを使用 - block_sample:
ランダム行サンプリングの代わりにランダムブロックサンプリングを使用する - method_opt:
ヒストグラムのサンプリング
FOR ALL INDEXED COLUMNS SIZE{integer | AUTO} - (AUTOと指定すると、列のデータ配分とワークロードに基づいて、ヒストグラムを収集する列を判断する
- degree:
並列度 - granualarity:
パーティションの場合のみ指定 - subpartition:
サブパーティションレベルの統計情報を収集
SQL統計情報の見方
SQL統計情報を分析する場合には、以下の点に注意して確認してください。
最終的に必要とされる行数に対して、アクセスしたブロック数:
索引を使用していないと、無駄なブロックのアクセス数が増える
最終的に必要とされる行数に対してフエッチした回数:
配列による結果行の取得を行っていないと、1回のフェッチで1行の読み込みしか行っていない場合がある
アクセスしたブロック数に対して、ディスクから物理的に読み込んだブロック数:
DBバッファキャッシュ上で、ブロックの共有ができていないと、物理読み込みの回数が増える
OLTP系のアプリケーションでは、90%以上のブロック共有が理想的といわれるが、共有できない理由として、次のような理由が考えられる
DBバッファキャッシュのサイズが小さいため上書きされる
適切な索引が作成されていないため、全表検索が選択される
パインド変数などが使われず、SQLの共有ができていない
ディスクソートが必要だった回数:
大量の行データに対してソートを行うのに対して、PGAに割り当てられた領域「SORTJREA_SIZEで指定」が小さく、一時表領域への読み書きが発生したことが考えられる
CPU時間に対するELAPSED TIME:
ELAPSED TIMEがCPU時間に対して長い場合、実際に処理をしているCPU時間よりもディスクIOの読み込み待ちや、ネットワークによる待ちに時間がかかっていることが考えられる これは、並行処理を行ううえで多重度が高くなったため、ディスクIOなどで競合が起きている可能性を示す
再解析が行われたか:
OLTP系のアプリケーションでは、なるべくSQL文が共有されている方が望ましい
再解析が行われていた場合、SQL文が共有できる記述になっていない、共有するための共有プールのサイズが不足していたなどの理由が考えられる
