

できるエンジニアになるためのちょい上DB術/第2章 概念設計
3.3 論理設計の手順(2/4)
B*treeインデックスのメンテナンス
B*treeインデックスは、検索時のパフォーマンスに対しては、使用方法によって劇的に効果をあげることがわかっています。
一方、更新時や挿入時には、思わぬパフォーマンスの劣化を伴う場合があります。
特に一括して大量のデータをロードする際や、大量データの更新時に、索引があるために数倍から十数倍もの時間がかかってしまう場合があります。
- 大量なデータのロードやimpon、大量なデータのinsenを行う前に索引を削除し、importまたは
大量inse止処理完了後、索引を再作成することを検討してみる - バッチジョブなどでしか使用しない索引は、オンライン処理暗は削除しておき、ジョブ実行直前に作成する
- 更新によって、索引の構造が崩れた場合、索引による効果が低くなる
「alterindex〜rebuild;」文を実行することによって高速に索引の再編成を実行することができます。
下記のような状態になると、結果的にアクセスする必要のあるブロック数が増え、パフォーマンスが悪くなります。
- 階層構造が深くなる
- 論理削除が増えて、ブロックの格納効率が悪くなる
上記の状態を確認するために、以下の処理を行います。
【STEP1】
「analyze index 索引名 estimate statistics validate structure;」文でインデックスの統計情報をindex_stats表に収集する
【STEP2】
index_stats表のdel_if_rowsは論理削除された索引エントリの数、if_rows列はリーフブロック内の索引エントリの数を表す
全索引エントリの数に対して論理削除の割合が20%を超えた場合、索引再作成文を発行し、最初から索引を作成しなおす
【STEP3】
index_stats表のheight列はB*tree索引の階層の高さを表す
論理削除が増加すると、それに伴って階層が高くなることがある
height列の値が4以上だった場合、索引再作成文を発行し、最初から索引を作成しなおす
索引再作成文:alter index索引名rebuild;
索引再作成文によって高速に索引を再編成できるのは、すでにソートされた状態の索引エントリ(既存の索引)を参照して新規に索引を作成しなおすからです。
ただし、同様の理由から、一時的に索引を格納する表領域の領域が索引サイズの2倍必要になることに注意してください。
Bitmapインデックスとは
Bitmapインデックスは、一意性の高くない列に作成しても有効に使うことができるとされています。
B*treeインデックス同様、どのような構造になっているのか、どのような場合に有効なのかを確認しましょう。
車体情報を管理する表cars表(行数10,000件)には車体の特徴を管理する列「color」「body」「door_num」「tire_num」などがあります。
これらの列の値は、一般的にすべて一意性はかなり低いと考えることができる列です。
これらの列にビットマップインデックスを作成した状態が図3-5です。
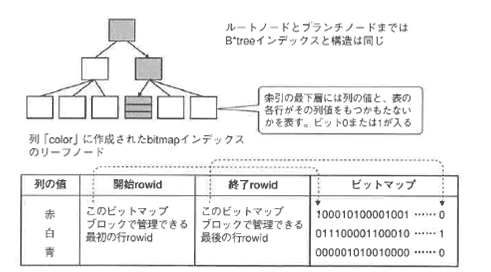
Bitmapインデックス作成時
B*treeインデックスとの違いはリーフノードの部分です。
リーフノードには、索引を作成した列の値と、このビットマップブロックで管理される最初のrowid、最後のrowid、表の各行がそれぞれその列値をもつ「1」か、もたない「0」かを表すビットが行数分格納されています。
また、連続するビット値は圧縮されて格納されます。
このため、ほとんどの場合、B*treeインデックスよりも領域は少なくてすみます。
インデックス使用時
検索条件に指定された値をもつ行は、リーフノードで値1をもつrowidです。
その後の処理はB*treeと同じです。B*treeとの違いは、主に下記の点です。
- 複数の検索条件を組み合わせた場合、それぞれの結果の論理積をとれば、該当するrowidを特定できる
- not条件式の場合も、ビットを反転させることによって索引を使用できる
- or条件の場合、B*treeインデックスは使用されない可能性が高かったが、Bitmapインデックスでは論理和を求めることによって使用することができる
- null値も列値の1つとして自動的に作成するため、null値検索も索引を使用できる
Bitmapインデックスの有効な使い方
SELECT 列名1, 列名2, 列名3 FROM 表名
WHERE color IN ('赤','黄')
and body !='wagon'
and tire_num=4
and door_num IN (4,5);
単体の列に対する問い合わせだけではなく、例のように、複数の列に対する条件式を組み合わせて問い合わせを行う場合、Bitmapインデックスの効果が発揮されます。
1.まず、各条件式ごとに、条件式の値に応じて行数分の0または1のあてはまるビットの組み合わせが作成される
2.次に各条件式をandまたはorで結合する
この結合処理が、Bitmapインデックスが高速処理できる部分になる
結合処理も、各条件式結果のビット行をビット演算で実行できるため、
瞬時に結合した結果の該当行が特定できる
Bitmapインデックスを作成した表にDML文が発行されたとき
Bitmapインデックスは更新処理を実行する際のパフォーマンスが悪いといわれます。
列値に対して更新処理が発生すると、関係するすべての列値を格納するブロックの圧縮が解凍されてからビット値が変更されます。
このとき、関係するすべての列値単位にロックがかけられるため、B*treeインデックスに比べてロックの範囲が大きくなります。
ビットマップ索引は、ロックがかけられる範囲が広いことから、B*treeインデックスに比較して更新系の処理が多発する表にはあまり向かないということができます。
Bitmapインデックスの特徴
- 索引を作成する対象の列が、一意性が低い列でも、複数の条件式を組み合わせて使用する場合、効果的
- 条件式が複数組み合わされていても(結合条件が多くても)パフォーマンスがよい
- not検索、null値模索、or条件を多用するような模索でも効果的
- B*treeと比較すると、更新ではコストがかかる
- B*treeと比較すると、格納効率がよい
- コストベースオプティマイザが有効になっていないと使用されない
- ユニークインデックスは作成できない
| B*treeインデックス | Bitmapインデックス | |
|---|---|---|
| 作成するのに適した列 | 一意性の高い列または列の組み合わせ | 一意性の低い列でも効果的 |
| 更新処理 | 比較的コストは低い | 比較的コストが高い |
| 更新時ロックの範囲 (索引の範囲) |
索引エントリ単位 | ビットマップセグメント単位 |
| WHERE句の制限 | null値の比較はできない or条件は使われない not条件は使われない |
null値の比較も可能 or条件も使用 not条件も使用 |
| 適しているアプリケーション | 少ない行を検索対象として処理するOLTP系 | 大量データをさまざまな角度から分析するDSS系 |
表3-10 B*treeインデックス v.s. Bitmapインデックス
クイズ1
この表に索引をつけるとしたら、どのような索引を作成するのが最も適切かa〜dから選びなさい。
- EMPLOYEES表
列名empno(primary key),ename,job,salary,comm,mgrno,deptno - アプリケーションで頻繁に実行されるselect文
1.select*from employees where deptno=20 and job="manager";
2.select*from employees where deptno=20;
3.select*from employees where ename is null;
4.select*from employees where empno=1043;
5.従業員数10,000人、部門数100、1レコード約75バイト - 選択肢(複数選択可)
a.deptno列に1つ、job列に1つずつ作成する
b.deptno列とjob列の複合索引を1つ
c.ename列にlつ
d.empno列に1つ
クイズ1の解答例
正解はbです。
deptno列とjob列をwhere条件式の中で使用しているので、この2つに索引をつけることを考えます。
a.は、それぞれの列に別に索引をつけています。
b.は複合索引という形で1つの索引にまとめています。
この場合、単独でも検索時に指定されるdeptno列を先頭にして、deptno列とjob列の複合索引を作成すると、2つの索引を作るよりも検索時のパフォーマンスはよくなります。
理由は、アクセスしなければならない索引の数が異なるため、必然的にアクセスするブロック数も少なくてすむからです。 ename列の条件式は、null値を探す問い合わせであるため、索引を使いません。
empno列は、empnoO列が主キーであるため、すでに索引は作成されているため、わざわざ作成する必要はありません。
