

できるエンジニアになるためのちょい上DB術/第2章 概念設計
3.3 論理設計の手順(2/4)
非正規化の検討
それでは、性能を出すための方策として、次に非正規化を検討してみます。
まず、非正規化とは何をすることなのか、注意すべき点は何かを明らかにします。
非正規化とは
非正規化とは、性能を上げるために「正規化を崩す」処理のことをいいます。
結果として設計に冗長性を追加することになるため、整合性を維持するための追加のアプリケーションが必要になります。
非正規化処理を行う際のルール
- 1.正規化を行った後に実施する
- 2.最適化の最後の手段として使用する
- 3.正規化を崩した箇所、理由などのドキュメントを残す
1.を行わないと、正規化と異なる部分が正確に特定できません。
冗長な部分が残っていると、更新時に整合性がとれなくなり、データベースとしての信頼性がなくなります。
2.については、先輩から教わってあらかじめ「こういう場合にはこうする」、と安易に最初から非正規化を選択する場合が多いのですが、冗長性は極力なくした方が、将来的なアプリケーションの拡張性を考えればよいといえます。
非正規化を行っても他に影響がない場合や非正規化をした方がよい場合を除いては、非正規化は必要悪と考えてください(詳細は後述)。
くれぐれも安易に非正規化を行わないようにしてください。
そして、非正規化を実施した場合には、後でメンテナンスをする人のために必ずドキュメントを残してください。
非正規化の種類
次のような非正規化の種類を考えることができます。
順に紹介しながら、非正規化を行う場合の注意点を説明すると同時に、非正規化をしてもよいかどうかについても考察します。
- エンティティの統合
- 繰り返し構造の使用
- テーブルの分割
- 導出項目をもたせる
- 重複項目をもたせる
エンティティの統合
正規化されたエンティティでは、結合処理に非常にコストがかかるため、結合エンティティ数が5を超えた場合、下記の条件にあてはまるようであれば複数エンティティの統合を検討します。
【条件】
1.エンティティどうしの結合処理が非常に多い
2.検索で使用される場合がほとんどで更新系の処理は少ない
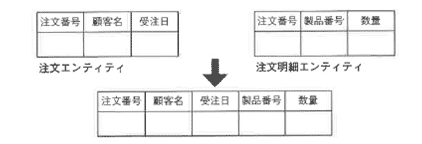
第1正規化された形から、繰り返し項目が再度出現してしまうため、繰り返し項目の部分(この場合だと顧客に関する部分)に変更が頻繁な場合には、お薦めできません。
Oracleデータベースの場合、正規化したまま元表は維持しておいて、マテリアライズドビューを作成し、参照時にはマテリアライズドビューを参照する方法を採ることができます。
マテリアライズドビューについては、第4章「物理設計」で紹介します。
繰り返し構造の使用
【条件】
繰り返し項目の回数が固定または一定数以下の場合、決まった回数分、繰り返し項目の格納を許す。
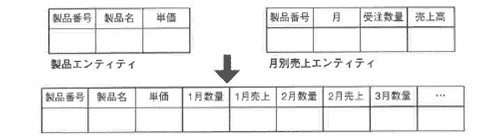
Oracleデータベースの場合、データの格納パターンとして、レコード長が時の経過とともに長くなっていくのは、構造的にあまりお勧めできません。
それは、このパターンに関しては、限界を超えて行長が伸びていくことに無制限に対応できるような仕組みにはなっていないからです。
(詳しくは第4章「物理設計」で説明します)
ところが、正規化された形(囲3-7の矢印の上部のような表のもち方)で値を管理していると、レポート処理などで矢印の下部のような表形式で出力するためにはUNIONという結合をせざるを得ず、パフォーマンス上非常にコストがかかることがわかっています。
そこで、このようなパターンでデータを格納するには、次のいずれかの方法を考えます。
- 繰り返し項目の回数が決まっているのであれば、その回数を決めてあらかじめ列数を定義する
その場合、あらかじめ領域を確保しておくために、ダミーの値を入力する - Oracleデータベースの場合、正規化したまま元表は維持しておいて、成形した形でマテリアライズドビューを作成する
参照時にはマテリアライズドビューを参照する方法を採る
(マテリアライズドビューについては第4章「物理設計」で紹介します)
テーブルの分割
【条件】
1.ピーク時のアクセス件数が非常に多く、10競合がおきやすい
2.1テーブル当たりのデータ量が非常に多い
3.サーバのロケーション条件によって、アクセスするテーブルの種類を分けることができる
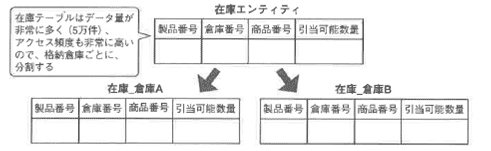
ある表に対して、更新処理が集中して実行されるため、ディスクIOが集中するような場合、テーブルを分割して物理的に別のボリュームに配置することを考えます。
図3-8の例では、在庫エンティティにアクセスが集中するため、倉庫ごとに在庫表を分けて別表としています。 これは、在庫表は倉庫別に異なるレコードを格納することが要件で明らかになっており、ユーザによってどの倉庫にアクセスするかがほほ固定されていることがわかっていたため、分けて管理してもよいという判断ができたためです。
ただし、全倉庫を串刺しにして在庫状態を検索したい場合には、分割した表をUNION句で結合するなどの必要がでてきます。
¥今回の場合、そのような在庫レコードを複数の倉庫をまたがって検索する要件の頻度が低かったため、実装できると判断しています。
また、Oracleデータベースの場合、表はあくまでも1つの表として定義しておき、格納するレコードを物理的に分けて格納する機能としてパーティション機能が提供されています。
在庫表の場合、表は在庫表として1つ定義しておき、倉庫番号によってパーティション分けをするリストパーティションを使用することができます。
導出項目をもたせる
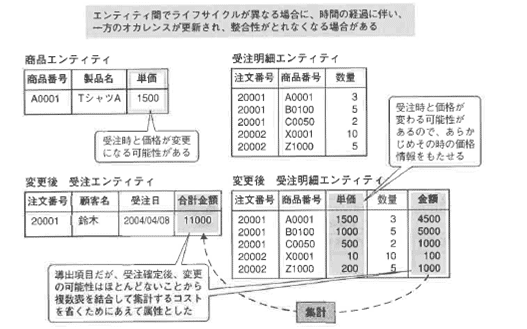
図3-9の例では、上段の商品エンティティと受注明細エンティティの関係をまず考えてみます。
受注明細から商品エンティティを参照して商品単価を取得することになっていますが、受注明細エンティティと商品エンティティでは、オカレンスのライフサイクルが異なります。
商品価格が変更されるタイミングと、注文処理に商品の価格が登録されて請求処理に回るまでのタイミングは同期しておらず、受注明細エンティティには受注時の商品単価の値が入っている必要があります。
受注後に商品価格が変更されたとしても、同期をとって商品単価が変ってしまうと契約違反になってしまいます。
正規化の観点からすると、両方のエンティティに目付データをもたせ、受注日付の商品単価を参照するようにするのが本来のやり方です。
しかし、それではパフォーマンス上の観点からコストがかかり過ぎるため、図3-9の「変更後 受注明細エンティティ」にあるように、単価という属性を設け、その時点の商品単価を挿入することにしました。 また、「変更確度牲エンティティ」にあるように、それぞれの受注伝票ごとの「合計金額」も、その時点での合計金額値が決まったらその後変更される可能性はほとんどないため、導出値ですが属性として加えました。 「可能性がほとんどない」というのは、ユーザへのヒアリングの時点で顧客からの受注情報変更頻度がたいへん低いという情報を得ているからです。
また、受注確定後は、出荷指示までの間にキャンセルが生じるか、返品処理などが発生しない限り、受注に関する変更はないからです。
しかも、キャンセルや返品処理の場合には、合計金額値には変更は加えず、キャンセルの場合には受注自体のキャンセル処理、返品処理の場合は合計金額値は変更せず、売上情報の変更と0円の新たな受注処理を追加することが決まっているため、変更処理はほとんどないことがわかります。
このように、導出項目を追加する際には、導出項目に関する変更処理が非常にまれな場合であることが明確にわかっている必要があります。
次に、導出項目を属性として加えている例をクイズで確認してください。
クイズ2
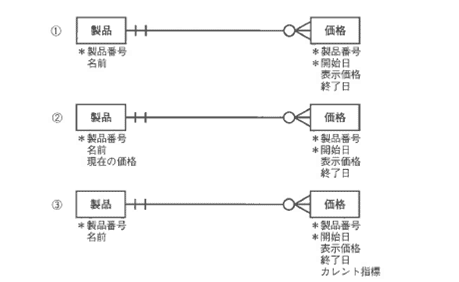
クイズ2の解答例
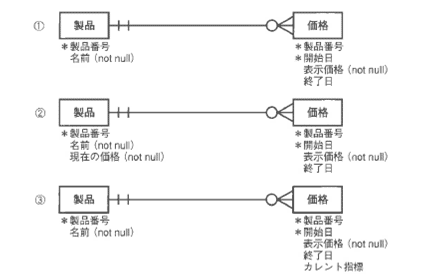
①は正規化したER図です。
製品価格が変更になった場合、価格エンティティに新しい価格情報を追加するだけでよい設計になっています。
ただし、製品の価格を検索したい場合、いつの時点の価格を知りたいのかという情報を入力し、その時点の価格情報を開始日と終了日を比較しつつ、該当製品のすべてのオカレンスと比較しつつ探す必要があります。
②は「価格」表に現在と過去の価格の両方を含めています。
1つの表の中に両方の情報を格納しておき、必要に応じて参照できるようにしてあります。
また、②では製品エンティティに冗長な属性「現在の価格」を含めることによって、現在価格を知りたいときに処理時間が最短になるようにしています。
ただし、製品価格が変更になった場合、価格エンティティにオカレンスを追加するとともに、製品エンティティには毎日日付が変わるごとに最新の価格情報が提供されているようにメンテナンス用のアプリケーションを追加しておく必要があります。
③は「価格」町中で親水の価栖を揺すためのコストを下げるため、「価格」表側に列「カレント指標」をもたせています。
製品価格が変更になった場合、価格エンティティにオカレンスを追加するとともに、毎日目付が変わるごとにその目付の価格情報が何であるかを示すためのカレント指標をメンテナンスするアプリケーションを追加しておく必要があります。
重複項目をもたせる
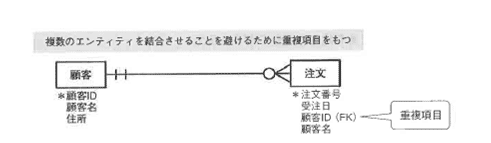
画面上で常に検索される項目で、頻繁に更新される可能性の低い項目については、複数のエンティティに重複してもたせておくのが一般的です。
特に、結合してもってくる属性が1または2の場合、結合するコストを避けるために重複項目をもたせます。
ただし、元のエンティティで変更された場合には、同期をとって変更するアプリケーションを追加する必要があります。
| 同一エンティティ内の導出 | 導出項目はもたない | |
| 別エンティティからの導出でライフサイクルが異なるもの | 導出項目をもたせる | DBトリガーなどを使い、整合性を維持 |
| 別エンティティからの導出でライフサイクルが同一のもの | 導出項目を可能な限りもたせない |
表3-11 導出項目をもたせるかもたせないかの判断基準
以上、性能を上げるための最適化の方法をいくつか紹介しました。
最適化に関する手法は、論理設計だけで行うものだけではありません。
物理設計でも方策として考えられることがいくつもあります。
あくまでも性能を上げるための非正規化は最後の手段と考えてください。
