

4.9 障害の種類とバックアップリカバリ
RAC構成では、すべてのブロックが、その状態を管理されている必要があります。
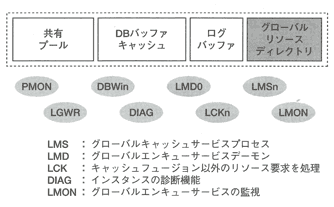
そこで、RAC構成をとった場合、シングルインスタンスでは存在しなかったような下記のようなメモリ上の構成要素(メモリ領域)およびサービスが存在します。
| メモリ上の構成要素(メモリ領域)およびサービス | 略称 | 説明 |
|---|---|---|
| グローバルリソースディレクトリ | GRD | GRD複数のインスタンスを横断して管理が必要なリソース(主にブロック)情報が格納されているSGA内のデータ構造 |
| グローバルキャッシュサービス | GCS | GCSキャッシュ上のブロックの一貫性を維持するために、ブロックに対するロックを管理 |
| クローバルエンキューサーヒス | GES | ブロック以外のリソースに対するロックを管理 |
表4-15 メモリ上のRAC固有のコンポーネント
グローバルに管理されるリソース(データブロック)には、それぞれのリソースを管理する「マスタ」が存在します(1ブロック当たり、いずれか1インスタンスがマスタノードとなる)。
グローバルリソースにアクセスする場合は、そのリソースのマスタに対してアクセス要求を行います。
新しいインスタンスが起動されたり、アクティブだったインスタンスが停止または異常終了した場合、障害が起きたマスタが管理していたリソース配分を変更するために再構成の処理が必要になります。
データベース内のすべてのブロックは、複数のインスタンスに分割されて、その状態が管理されています。
これを管理している領域が、上記のGRDと呼ばれる、メモリ上の共有領域です。
あるインスタンスが障害を起こした場合、障害を起こしたインスタンス上で管理していたGRD上のブロック情報を、残ったインスタンスで再配分する必要があり、この間は他のタスクは一切行うことができないため、インスタンス障害からの回復時には、通常のシングルインスタンスよりも時間がかかってしまいます。
RAC固有のバックグラウンドプロセスを図4-58に示します。
Cache Fusion処理のログや、障害発生時のログでよく見かける名前です。
RAC環境における障害回復
RACは、対障害対策という意味で、非常に有効なソリューションです。
それでは、シングルインスタンスの場合と、障害回復の面でどのように違いがあるのか、またはないのかを見ていきます。
まず、障害回復に使うログファイルについてみていきます。
REDOログ
- インスタンス障害暗、障害が起きていないノードからアクセスし、障害ノードの回復処理を行う必要があるため、共有ディスク上に配置します
- インスタンスごとの識別を行うため、パラメータファイル中で各インスタンスに定義されたスレッド番号を使って(thread=n n:インスタンス番号)インスタンス番号ごとに管理されます
- 各スレッドごとに最低2グループが必要です
アーカイブログ
- RAWデバイス上に作成することはできません
- メディア障害時、障害を回復するノードからアクセス可能なファイルシステム上に作成するのが望ましい(NFS、OCFSなどを利用)です
- ファイル名にスレッド番号(%Tまたは%t)、ログ順序番号(%Sまたは%s)を記述することによって、インスタンス別に管理することができます
インスタンス障害からの回復
【STEP1】
障害の検出
【STEP2】
ノードおよびリソースの再構成
【STEP3】
REDOの読み取り
【STEP4】
リカバリに必要なブロックの確保
【STEP4】
REDOの適用
- リカバリは、最新のパストイメージブロックから開始することができるため、最小のリカバリ時間で回復できるようになっています
- 異常終了したすべてのインスタンスのREDOスレッドをマージしてリカバリします
- STEP2のリソースの再構成では、GCSが再構成され、LMSnがマスタを失ったリソースを再マスタ化します
- STEP3では、障害が発生したインスタンスのREDOログをSMONが読み取り、リカバリが必要なブロックのみを識別します
- STEP2~STEP4の間はデータベースはすべてのリソースに対してブロックされた状態になります
最後のブロックされた状態になるという部分が、シングルインスタンスと異なる部分であり、インスタンス全体が停止したように見える部分(時間帯)です。
上記のように、マスタの再構成作業を行っているために、停止しているように見えるという点を理解してください。
メディア障害からの回復
メディア障害からのリカバリに関しては、シングルインスタンスと大きく異なるところはありません。
障害を回復するインスタンスから、すべてのインスタンスのアーカイブログファイルおよびREDOログファイルを参照できる必要があります。
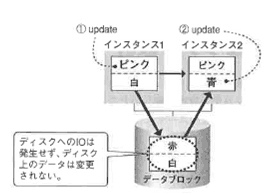
ブロック競合が発生しても、ディスクへの書き込みは発生しないため、IOによるパフォーマンスの劣化は回避されています。
ノード間通信を使ったブロック移動が大量に生じた場合、ネットワークによるパフォーマンスの劣化が起きる可能性があるので、これをなるべく避ける必要があります。
パフォーマンスの低下が起こるのは、異なるインスタンスから同じブロックに対して更新要求の競合が発生した場合、更新と読み取り一貫性の競合が発生した場合です。
対策として、それぞれのインスタンスごとに接続するユーザをアプリケーション別に分け、同じブロックを使う可能性の高いユーザは、なるべく同じインスタンスに接続するようにします(アプリケーションパーティショニング)。
また、ブロックサイズを小さくし、1つのブロックに格納する行数を少なくし、ブロックの競合が発生する確率を低くする方法も有効です。
