

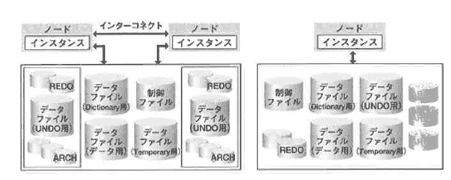
4.9 障害の種類とバックアップリカバリ
CacheFusion
次に、RACで最もパフォーマンス上問題となる更新処理と更新処理が競合を起こした場合の解決策を紹介します。
Oracle9iRACでは、すべてのブロック競合に対してCacheFusionを適用し、従来までの共有ディスククラスタの欠点を改善しています。
- 高速なノード間通信によりデータブロックを転送
- ディスクlOを介さずにデータの同期を実現
- Read/Read、Read/Write、Write/Writeなどすべての競合に対して適用
Cache Fusionの仕組みを知ることによって、更新の競合が起きた場合のパフォーマンスの劣化はどこに原因があるかを理解することができます。
より効率よくRACを使うために、CacheFusionの仕組みを理解してください。
図を使ってCacheFusionの仕組みを説明します。
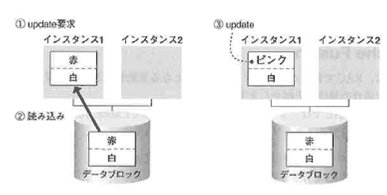
まず、Oracle8iまでの動きを配明します。
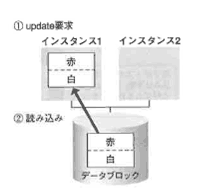
Oracle8iまでは、機敏のインスタンスで同じプロッタに対して更新競合が起きた場合、更新後のブロックを一度ディスクに書き出すことによって同期をとっていました。
更新競合が起きるたびにディスクヘの書き込みが発生し、パフォーマンス上のボトルネックになっていました(図4-50)。
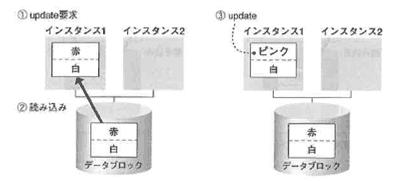
インスタンス1であるブロックに対する更新要求が発生したので(①)、ブロックをディスクからインスタンス1に読み込みます(②)。
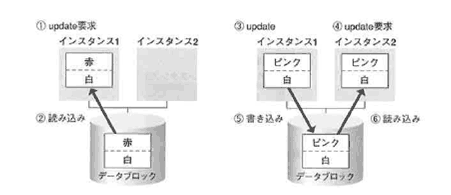
すると、更新したブロックは、一度ディスクに書き戻され(⑤)、更新後の状態を全データベースで共有できるようにした後、インスタンス2に読み込まれます(⑥)。
Oracle8iまでは、更新処理が複数インスタンスで競合すると、必ずディスクヘの書き込み処理が生じていたため、更新処理が複数インスタンスから同時に発生するようなアプリケーションでは、パフォーマンス上あまり効果があがらないという状況になっていました。
Cache Fusionでは、このようなパフォーマンス上の問題を解決するため、更新処理が競合を起こした場合、ブロックをノード間ネットワークを使って拘束に転送することによってディスクIOを提言し、パフォーマンスの改革を図っています。
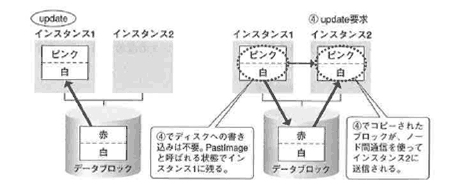
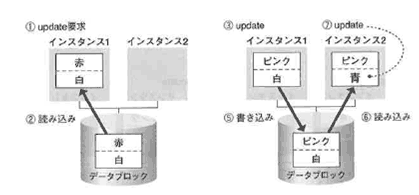
次に、同じブロックの違う行「白」に対して、インスタンス2から更新要求が出されました(④)。
すると、更新されたブロックは、ノード間ネットワークを通じて、インスタンス2に直接転送されます。
一方、インスタンス1には、インスタンス2の障害に備えて、インスタンス1で更新した状態のままパストイメージという状態で残されます。
インスタンス2で、「白」から「青」に更新処理が行われます(⑤)。 この間、ディスクヘの書き込み処理は一切行われません。
Cache Fusionが更新と更新の競合でも適用されることによって、ブロック競合に対する性能上の解決策として効果が高いことがわかると思います。
ただし、ここで注意したいことがあります。
1つは、インスタンス障害時の回復処理です。ディスクに書き込みを行っていないため、ディスク上のブロックから回復処理をすべて適用していくのでは非常に時間がかかってしまいます。
そこで、先ほどの図にあったように、パストイメージとよばれるブロックを、カレントインスタンスの前のインスタンスに残しておき、そこから回復できるようにしています。
このように、RACの場合、すべてのブロックがどのインスタンスによって現在どのような処理をされているか、現在のロックのレベルは何で、どのインスタンスがカレントでロックを取得しているのかといった状態をすべて管理される必要があります。
もう1つは、インスタンス間ネットワークのデータ量と転送速度が、RACパフォーマンスの鍵を握るという点です。
これに対しては、ネットワーク自体の速度向上と、アプリケーションパーティショニングというアプリケーションを実行するインスタンスを分ける操作が解決策となります。
これらの事柄について、続けて見ていきます。
