

4.5 パフォーマンスアップ
4.5.4 実行計画の読み方とSQLチューニングのための考慮点
実行計画を読む場合に、着目すべきポイントを以下に示します。
| アクセス方法 | 実行計画での表示 |
|---|---|
| 全件検索 | TABLE FULL SCAN |
| 索引によるアクセス | INDEX UNIQUE SCAN(ユニークインデックス)+TABLE ACCESS BY INDEX ROWID(索引エントリのROWIDを使って表のブロックにアクセス) |
| lNDEX RANGE SCAN(範囲検索、1つの値で複数の索引エントリがある場合)+TABLE ACCESS BY INDEX ROWID(索引エントリのROWIDを使って表のブロックにアクセス) | |
| 索引の高速スキャン | INDEX FAST FULL SCAN |
表4-4 表へのアクセス方法
最終的に取得する行が表の全行でない場合、適切な索引によって行を絞り込み、アクセスするブロック数を減らすことができます。
全件検索、索引検索については第3章「論理設計」で詳細に説明したので、ここでは適切な索引を作成するポイントを説明します。
全件検索より、索引を使って検索した方がアクセスするブロック数が少ない場合、どちらが高速かは、物理アクセス回数が少ない方が速いといえます。
全件検索の場合、マルチブロックリードを行うので、対象行を取得するために必要なアクセス回数は、ブロックを取得するための給アクセス回数になります。
全件検索の場合に1回のアクセスで取得するブロック数は、初期化パラメータdb_file_multiblock_read_countで指定します。
デフォルトは8ブロックです。
一方、索引を使った場合、1回のアクセスで取得できるブロック数は1ブロックです。
一般的には、WHERE条件式で列値を指定して、全行のうち10%以下に放り込める場合、索引の作成が有効と考えられています。
複数列の組み合わせで索引を作る場合、索引を作成する際の列の順序が重要です。
最初に指定する列は、必ずWHERE旬で条件式に使用される列である必要があります。
どの列も同じ程度に指定される場合は、より一意性の高い列を先に指定します。
【CASE1】値によって一意性の高い列または列の組み合わせを条件式で指定する
「4.5.2 統計情報の収集」で説明したように、列にある値を指定した場合のみ、行を絞り込む一意性が高くなる場合、ヒストグラム統計を収集する必要があります。
このように備によって、索引の使用/未使用をオプティマイザが判断する必要がある場合には、値にパインド変数を使用してはいけません。
パインド変数を指定した場合、ヒストグラムの統計情報は参照されないためです。
【CASE2】NULL値を多く含むが、それ以外の値の一意性は高い列
B*tree索引ではNULL備には索引エントリを作成しません。
NULL値の模索には索引を使いませんが、列値を指定した場合に絞り込むことができるのであれば、索引の作成は有効です。
【CASE3】他表と結合する外部キー列
分析業務を行う際のファクト表(売上表など)の、マスタ表と結合する際の外部キー列に、BITMAP索引を作成することは非常に有効です。
結合のための条件式、および複数の条件式の組み合わせでファクト表の行を絞り込む際、列値の一意性は高くなくても、BITMAP索引の場合、列の組み合わせで行を特定することが容易にできるため、非常に効率よく行を選択することができます。
結合の順番
代表的な結合の種類としては、ネステッドループ、ハッシュジョイン、ソートマージの3種類を挙げることができます。 結合のコストは、どの表を先に検索するか、表をどの順で結合するかが大きく影響します。 特に、結合の種類として、結合は2表とは限らず、3表以上になる場合も多々あります。 表の行を放り込む条件式も指定されている場合、次のことがいえます(以下の説明はネステッドループを使用した場合を想定しています)。
- 1. 絞り込み条件によって行数が絞り込まれた表の順に結合する
- 2. 結合する列と絞り込み条件に指定された列の複合索引が有効
次のSQL文を考えてください。

【CASE1】
emp表のhiredate列の値にあてはまる行100行の結果を取得します。
100行それぞれに含まれるdept_idをもとに、dept表のdept_name='営業1課'にあてはまる行を絞り込むことによって、結果の行集合が20行になります。
結果として求められた20行それぞれのlocation_idをもとに、location表からcityを求めます。
このような結合の順番を実現するためには、以下の索引を作成します。
emp表のhiredate列に絞り込み用の索引
dept表のdep_id列とdep_name列に結合&絞り込み用索引
location表のlocation_id列
【CASE2】
dept表のdep_name='営業1課'に該当する行を絞り込み、4000行の結果行集合を取得します。
dept表4000行のlocation_id列の値をもとにlocation表を検索し、location_name列を取得します。
最後に4000行のdep_id列値とemp表のdep_id列の値をつき合わせ、emp表のhiredate列の値が2005/04/01と2005/12/31の間にあてはまる行20行を求めます。
このような結合の順番を実現するためには、以下の索引を作成します。
dept表のdept_name列に絞り込み用の索引
location表のlocation_id列に絞り込み用の索引
emp表のdept_id列とhiredate列に結合&絞り込み用の索引
また、結合する際に、複数の表に対する絞り込み条件がある場合、結合に使用する索引は、絞り込み条件と結合列の複合索引である必要があることに注意してください。
単一の絞り込み用の索引だけの場合、結合した結果行集合の中から、条件に合うものを索引を使ってフィルタリングすることになってしまいます。
結合の種類
結合の種類は、大きく分けてネステッドループ結合、ソートマージ結合、ハッシュ結合の3種類があります。
それぞれの特徴を理解し、SQL文の処理に応じて使い分ける必要があります。
それぞれの処理概要を説明します。
ネステッドループ結合(Nested Loop Join:NLJ)
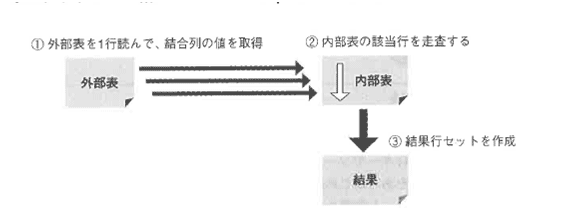
先に読み取る表を外部表または駆動表、次に読み取る表を内部表といいます。 外部表から1行読み込み、その結合列の値を読み取り、内部表を走査します。 内部表の走査が完了すると、外部表から次の1行を読み込みます。 これを外部表の行がなくなるまで繰り返します。
走査のコストを少なくするためには、以下の点に気をつける必要があります。
- 内部表の走査は外部表の行数と同じ回数繰り返されるので、外部表の行数はできるだけ少ないほうがよい
- 内部表へは繰り返しアクセスされるため内部表の結合列に索引があればソート済みの行にアクセスするため、さらに結合効率をあげることができる
ネステッドループ結合の負荷は以下の式で求められます。
ヒント文は、/*+use_nl(table名)*/として指定した表を内部表として使用させます。
ソートマージ結合(Sort Merge Join:SMJ)
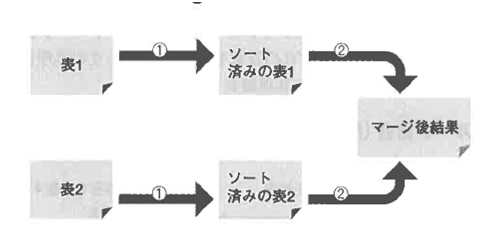
ソートマージ結合のアルゴリズムでは、表1、表2両方の読み込みが必要です。
さらにそれぞれを結合キーでソートした上で2つの表をマージします。
このように結合条件の左右両表をあらかじめ結合キーで並び替える必要がありますが、適切な索引がある場合にはソート作業をスキップさせることができます。
索引は、結合列と、SELECT句で指定する列の複合索引を作成すると、より効果的です。ソートマージ結合の負荷は以下の式で求められます。
COST(SMJ)=表1の読み込みコスト+表1のソート+表2の読み込みコスト+表2のソート
ハッシュ結合(Hush Join:HJ)
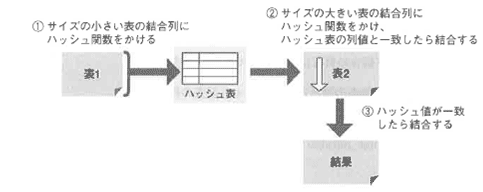
サイズの小さな方の表の結合列にハッシュ関数をかけ、ハッシュ表と呼ばれる結合のための作業表をメモリ内に構築します。
メモリ内に収まらないときは収納可能なサイズに表を分割して、部分ごとにハッシュ表を作成し、取り替えながら結合を進めます。
次に大きな表から読み込んだ行の結合列値に対してハッシュをかけ、該当値がハッシュ表に存在すれば結合を行います。
これを大きな表の行数分線り返します。
1行に対して読み取り作業は1回しか行いません。
ハッシュ結合の負荷は以下のとおりです。
COST(HJ)=表1の読み込みコスト+表2の読み込みコスト+ハッシュ表作成コスト
ハッシュ結合とネステッドループ結合の使い分け
一方、結果行集合が数行の場合で、内部表(後で検索される表)が索引などを使用して絞り込むことができる場合は、ネステッドループを使用すると、大幅に性能が向上する場合があります。
ハッシュ結合とネステッドループ結合の使い分け
しかし、列値にNULLが含まれていて、その行もソート対象の行になっている場合、NULL値には索引エントリが作成されないので、索引が使用できず、全表検索が選択されます。
もし、ソート対象の列にNULL値を許さない、という制約を付与しても良いのであれば、NOT NULL制約を付与した上でその列に索引を作成してください。
または、SELECT文中のWHERE条件句のなかで「ソート対象の列IS NOT NULL」式を加えた上で、ソート旬にその列を指定してください。
